Synthetic data generation with mice
Methodology & Statistics @ Utrecht University
November 4, 2022
Being wrong about the truth
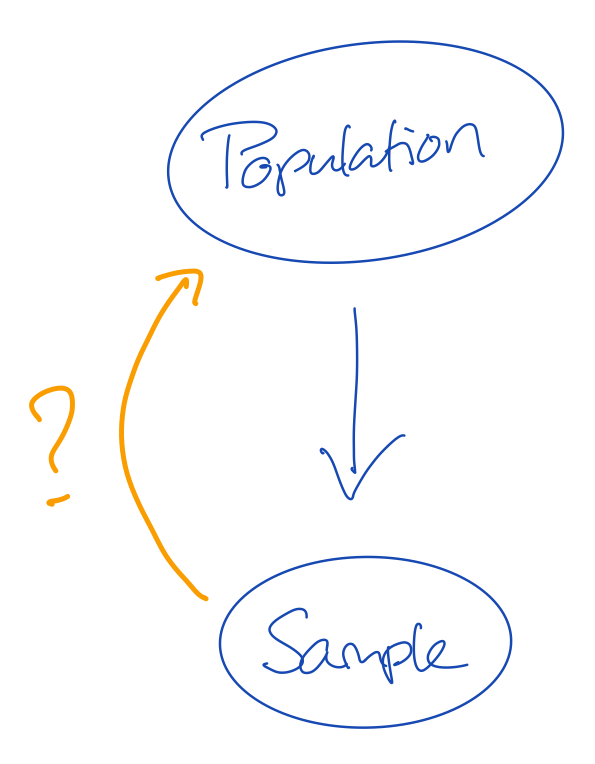
- The population is the truth
- The sample comes from the population, but is generally smaller in size
- This means that not all cases from the population can be in our sample
- If not all information from the population is in the sample, then our sample may be wrong
Q1: Why is it important that our sample is not wrong?
Q2: How do we know that our sample is not wrong?
Solving the missingness problem
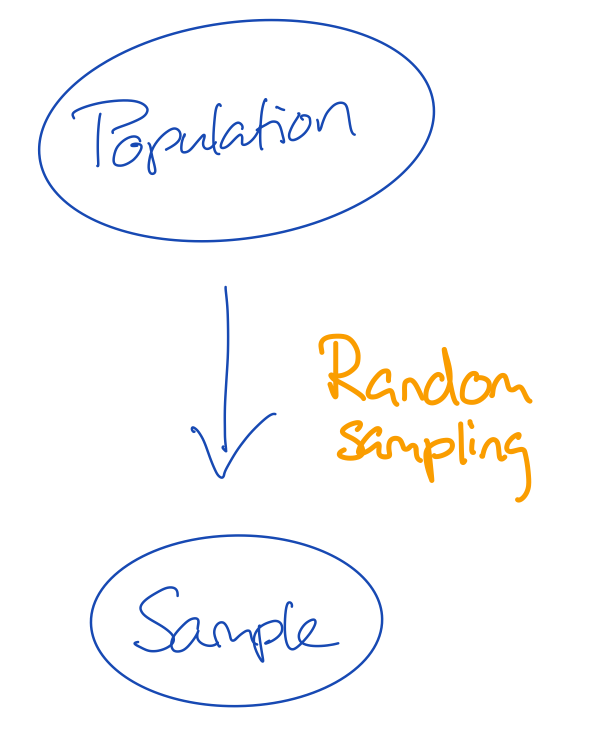
- There are many flavours of sampling
- If we give every unit in the population the same probability to be sampled, we do random sampling
- The convenience with random sampling is that the missingness problem can be ignored
- The missingness problem would in this case be: not every unit in the population has been observed in the sample
Q3: Would that mean that if we simply observe every potential unit, we would be unbiased about the truth?
Sidestep
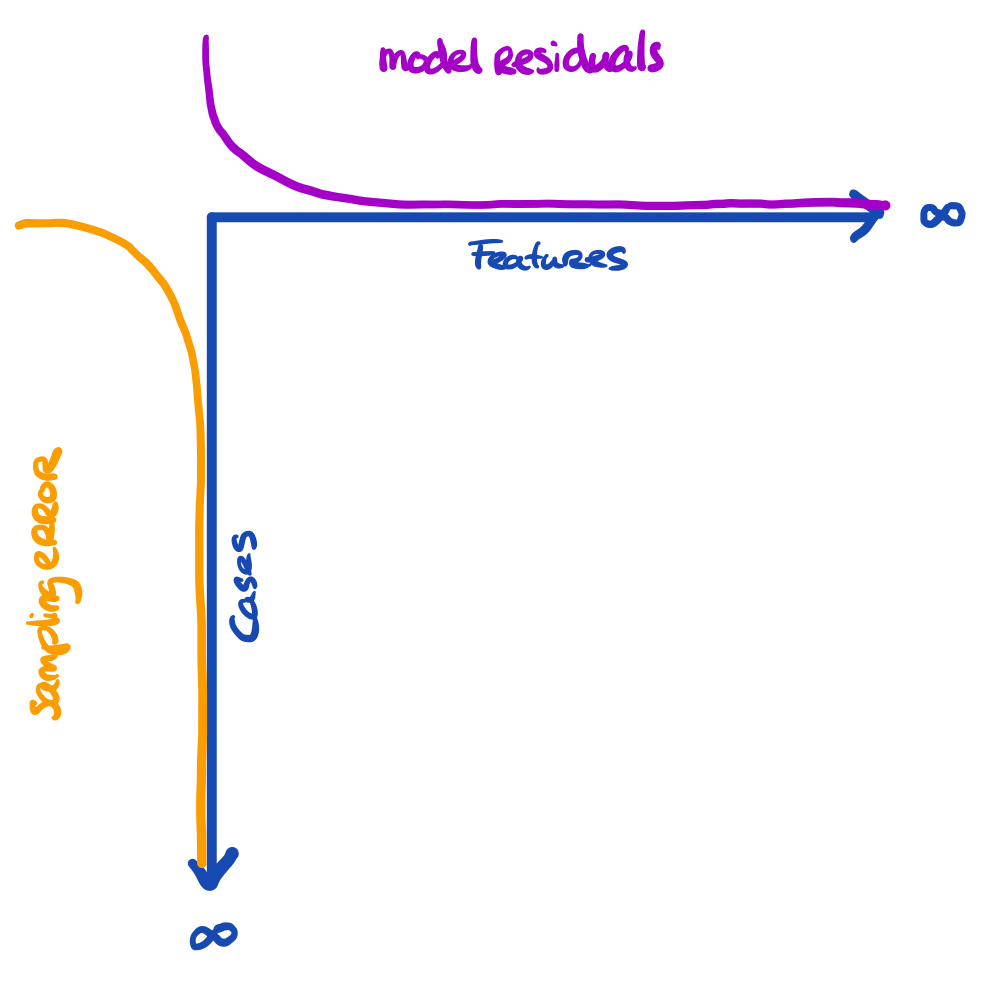
The problem is a bit larger
We have three entities at play, here:
- The truth we’re interested in
- The proxy that we have (e.g. sample)
- The model that we’re running
The more features we use, the more we capture about the outcome for the cases in the data
Sidestep
- The more cases we have, the more we approach the true information
All these things are related to uncertainty. Our model can still yield biased results when fitted to \(\infty\) features. Our inference can still be wrong when obtained on \(\infty\) cases.
Sidestep
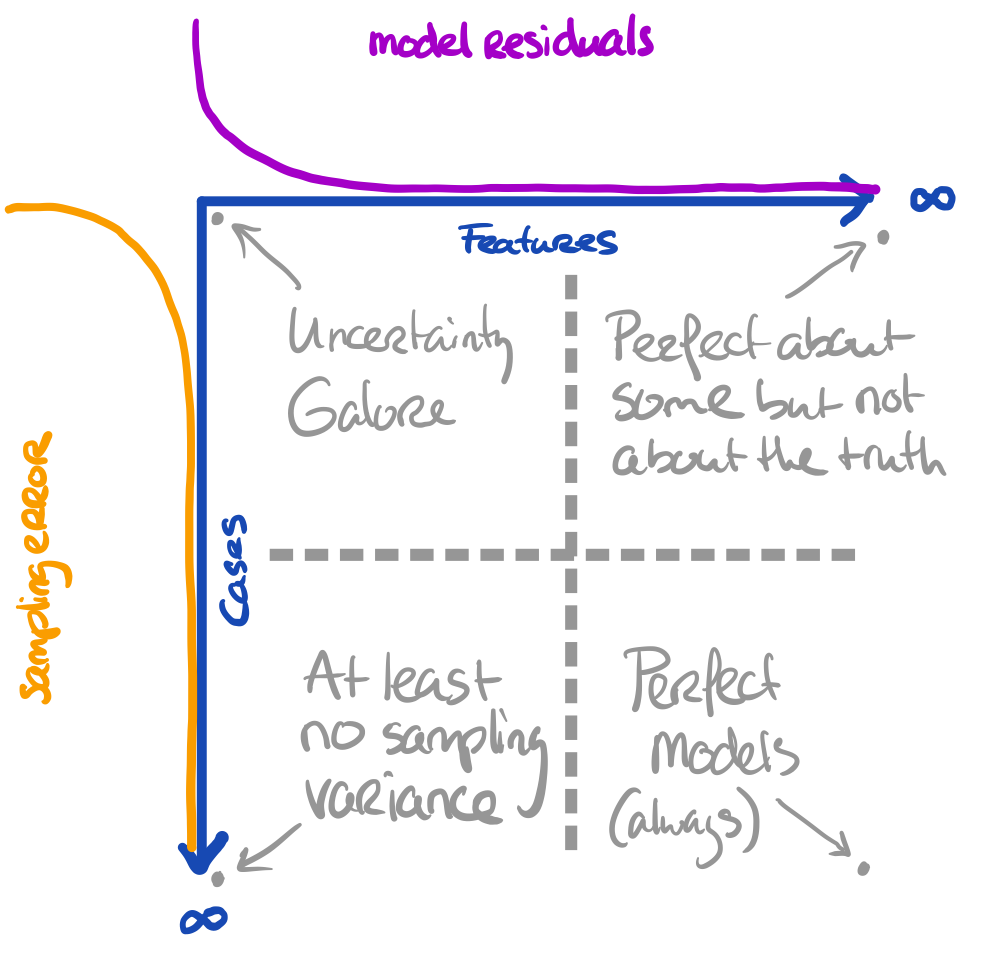
Core assumption: all observations are bonafide
Uncertainty simplified

When we do not have all information:
- We need to accept that we are probably wrong
- We just have to quantify how wrong we are
In some cases we estimate that we are only a bit wrong. In other cases we estimate that we could be very wrong. This is the purpose of testing.
The uncertainty measures about our estimates can be used to create intervals
Confidence intervals
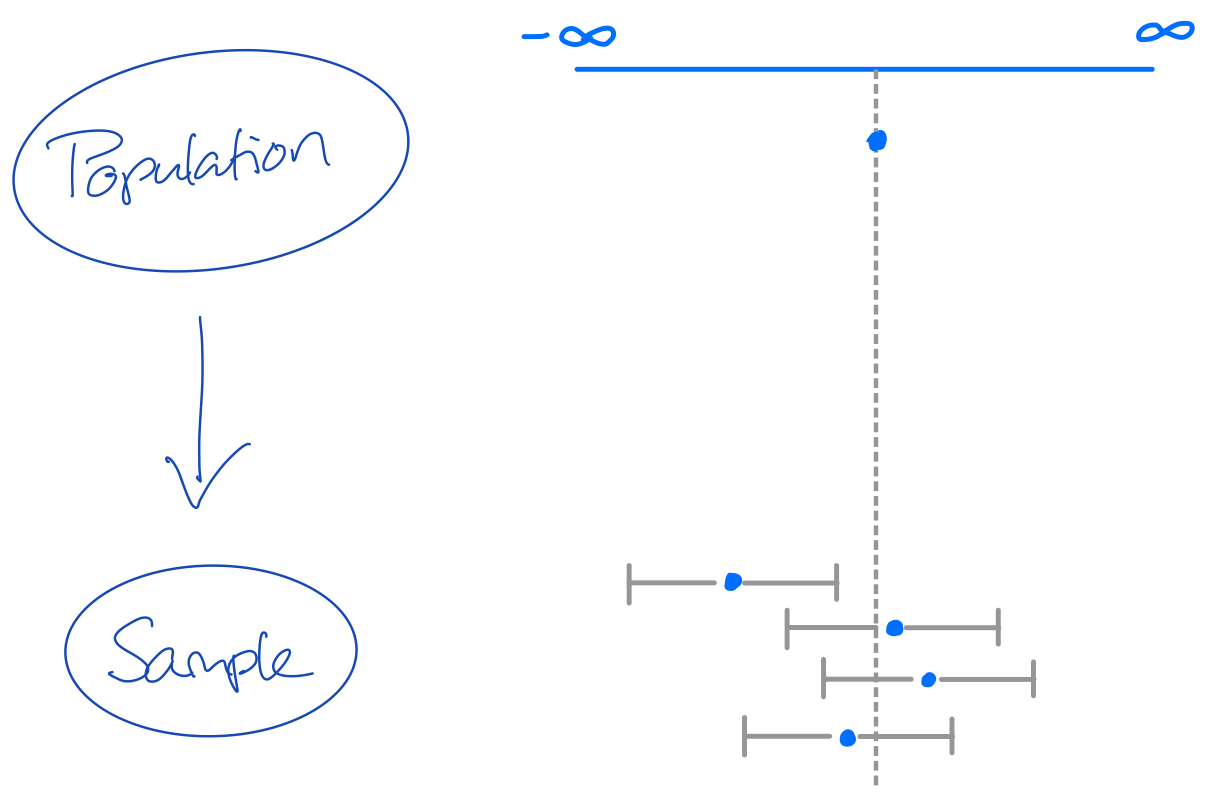
Confidence intervals can be hugely informative!
If we sample 100 samples from a population, then a 95% CI will cover the population value at least 95 out of 100 times.
If the coverage \(<95\): bad estimation process with risk of errors and invalid inference
If the coverage \(\geq 95\): inefficient estimation process, but correct conclusions and valid inference. Lower statistical power.
The holy trinity
Whenever I evaluate something, I tend to look at three things:
- bias (how far from the truth)
- uncertainty/variance (how wide is my interval)
- coverage (how often do I cover the truth with my interval)
As a function of model complexity in specific modeling efforts, these components play a role in the bias/variance tradeoff

Hello, dark data

Let’s do it again with missingness

We now have a new problem:
- we do not have the whole truth; but merely a sample of the truth
- we do not even have the whole sample, but merely a sample of the sample of the truth.
Q4. What would be a simple solution to allowing for valid inferences on the incomplete sample?
Q5. Would that solution work in practice?
Let’s do it again with missingness
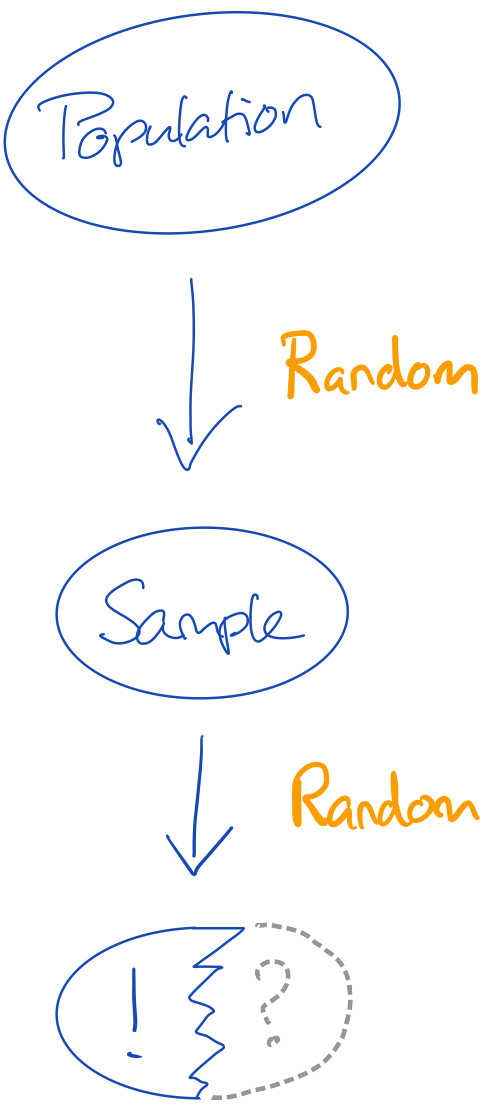
We now have a new problem:
- we do not have the whole truth; but merely a sample of the truth
- we do not even have the whole sample, but merely a sample of the sample of the truth.
Q4. What would be a simple solution to allowing for valid inferences on the incomplete sample?
Q5. Would that solution work in practice?
Multiple imputation
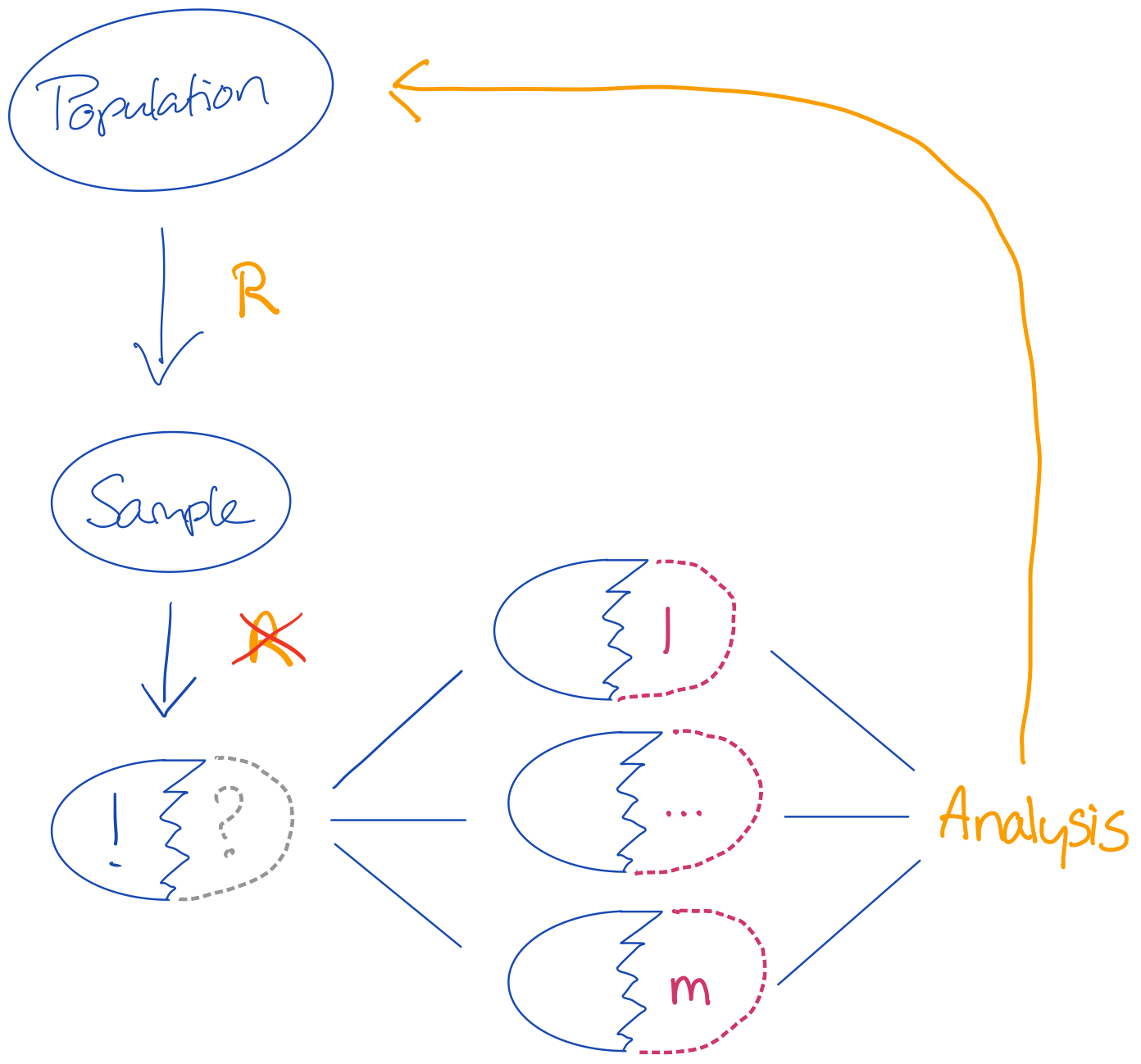
There are two sources of uncertainty that we need to cover:
- Uncertainty about the missing value:
when we don’t know what the true observed value should be, we must create a distribution of values with proper variance (uncertainty). - Uncertainty about the sampling:
nothing can guarantee that our sample is the one true sample. So it is reasonable to assume that the parameters obtained on our sample are biased.
More challenging if the sample does not randomly come from the population or if the feature set is too limited to solve for the substantive model of interest
Demonstration of imputation
To impute and analyze the same model with mice, we can simply run:
boys %>%
mice(m = 5, method = "cart", printFlag = FALSE) %>%
complete("all") %>%
map(~.x %$% lm(hgt ~ age + tv)) %>%
pool() %>%
summary() term estimate std.error statistic df p.value
1 (Intercept) 71.4996462 0.62149605 115.044409 735.07926 0.000000e+00
2 age 6.9612293 0.09409268 73.982690 78.04537 0.000000e+00
3 tv -0.4650875 0.08986812 -5.175222 49.56070 4.126098e-06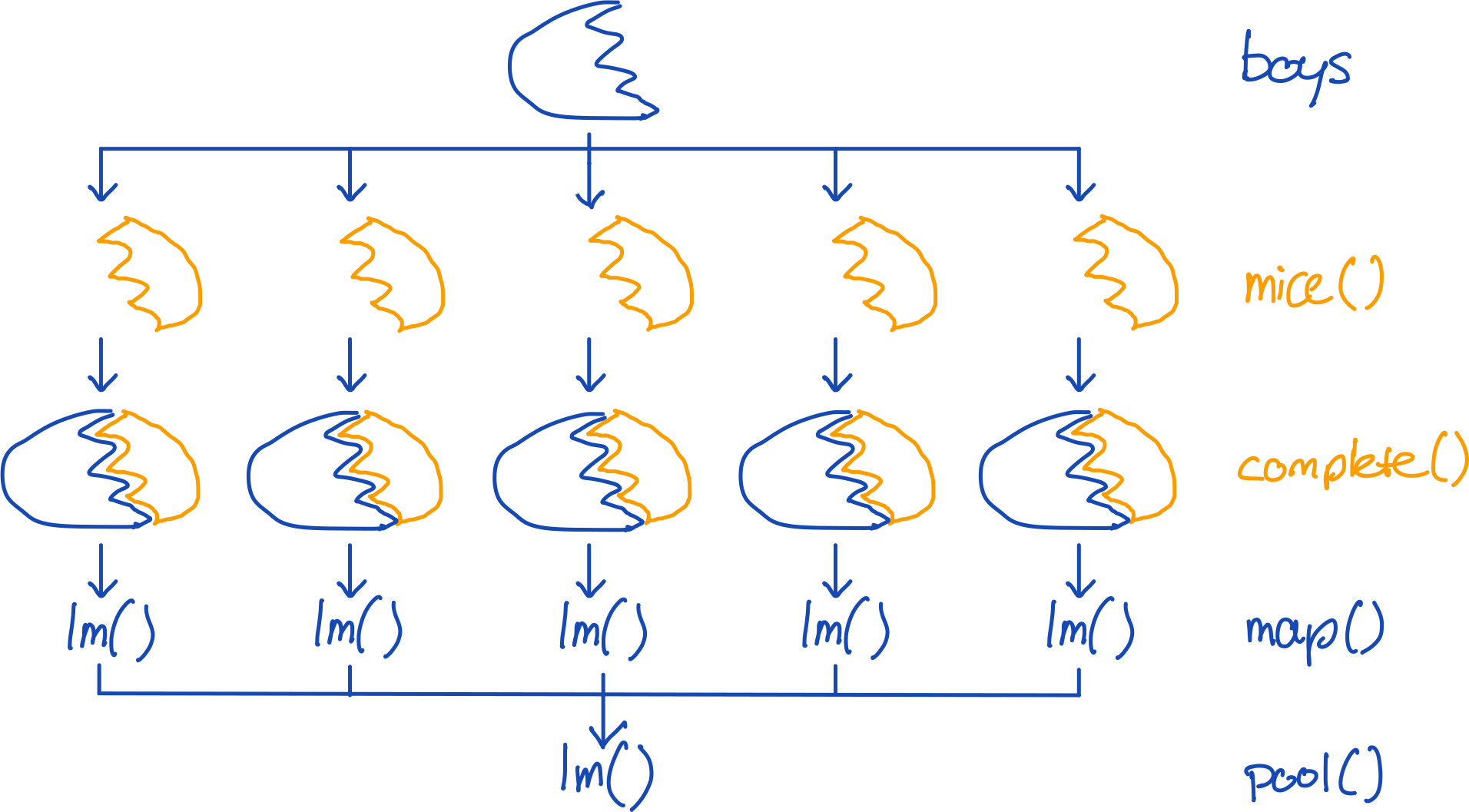
Imputation vs Synthetisation
Instead of drawing only imputations from the posterior predictive distribution, we might as well overimpute the observed data. 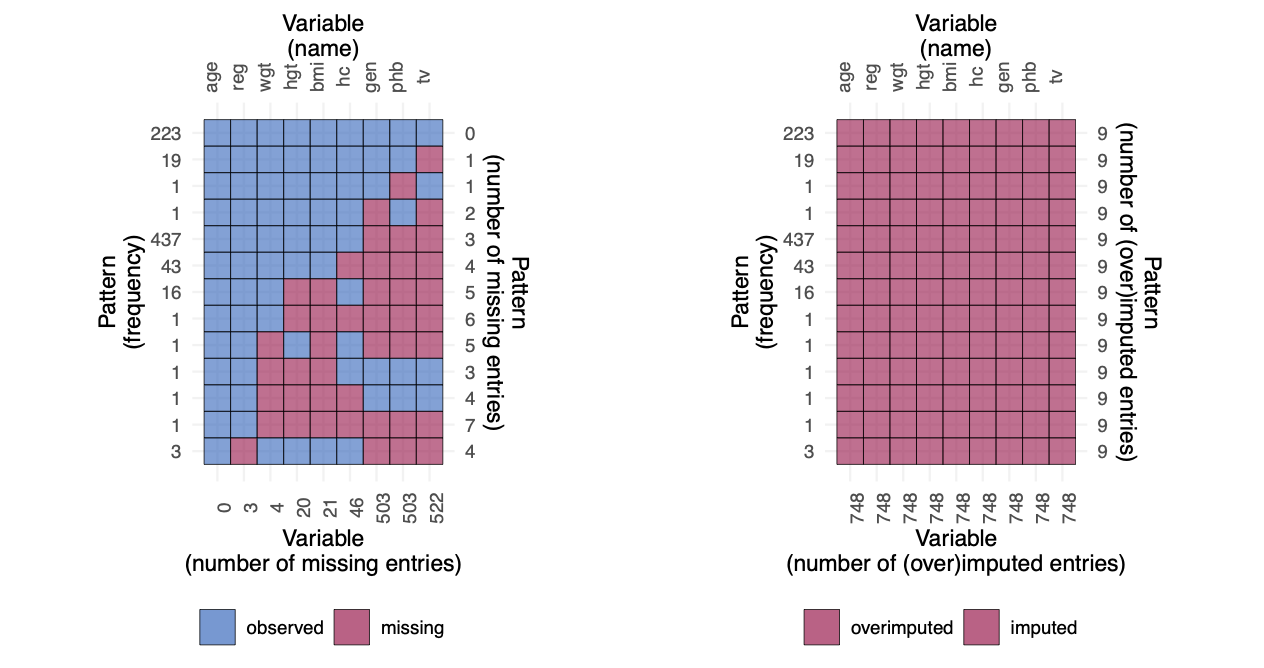
How to draw synthetic data sets with mice
boys %>%
mice(m = 5, method = "cart", printFlag = FALSE, where = matrix(TRUE, 748, 9)) %>%
complete("all") %>%
map(~.x %$% lm(hgt ~ age + tv)) %>%
pool() %>%
summary() term estimate std.error statistic df p.value
1 (Intercept) 71.1914095 0.7962174 89.412020 43.37485 0.000000e+00
2 age 6.9914529 0.1141189 61.264648 45.55541 0.000000e+00
3 tv -0.4684145 0.1018189 -4.600469 42.92353 3.713106e-05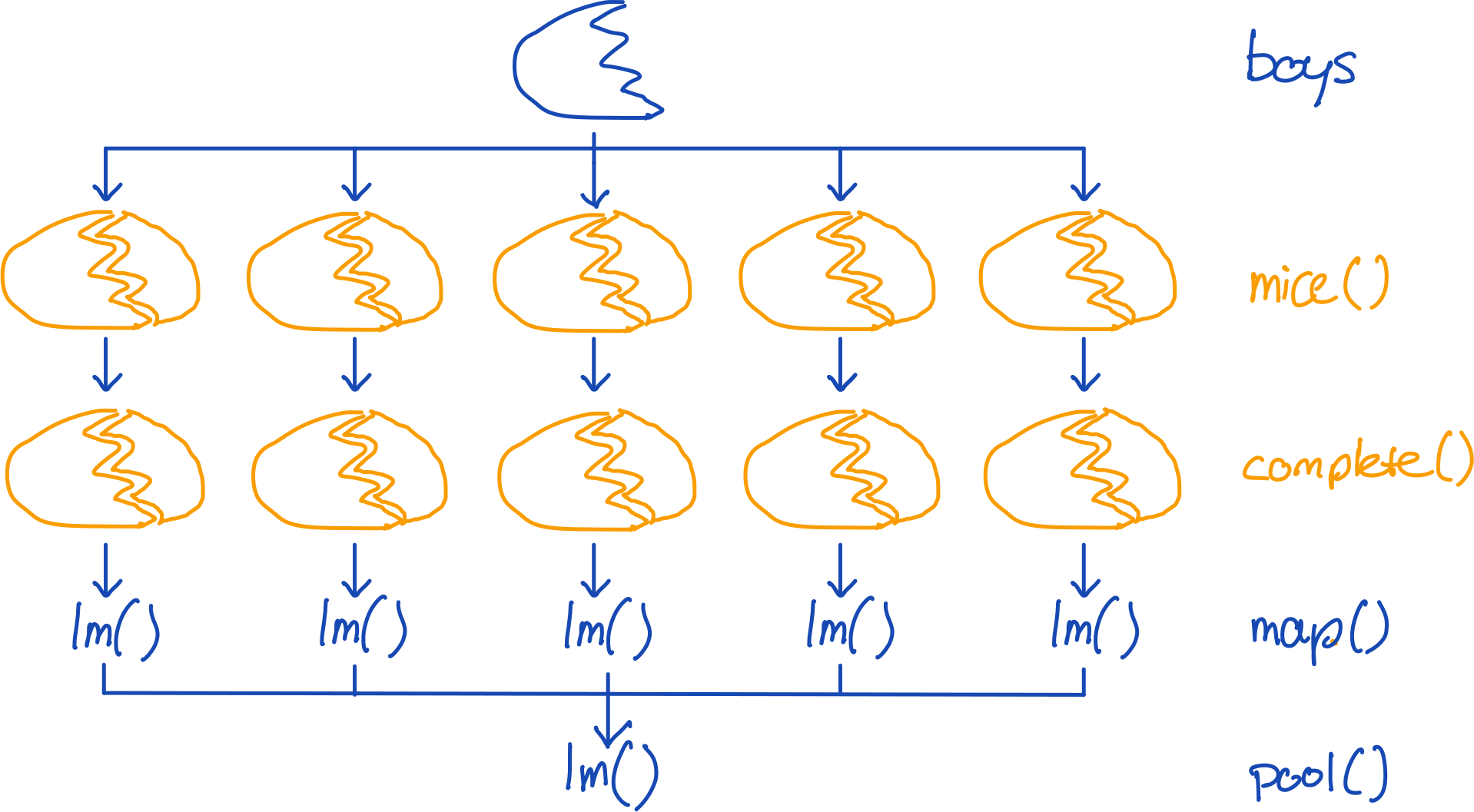
But we make an error!
End of presentation

![]()