library(MASS) # randomization functions library(magrittr) # pipes library(dplyr) # data manipulation library(ggplot2) # plotting library(glmnet) # penalized regression library(VariableScreening) # high-dimensional data library(caret) # flexible machine learning library(plotmo) # informative plots library(coefplot) # coef stuff library(DT) # fancy tables
Data Science and Predictive Machine Learning
Packages used in this lecture
So far
We have learned about ridge regression
Ridge regression poses - next to the usual minimization of the sum of squared deviations - a restriction on the sum of the coefficients.
- The more restricted the sum of coefficients is, the more the coefficients must shrink to zero.
- The least restrictive the penalization is, the more the solution resembles least squares estimation.
- The ridge penalty shrinks the coefficients of correlated predictors towards each other. This is not necessarily what you would want.
It is not difficult to understand that the more you shrink the coefficients, the more bias you will induce. However, with the higher bias comes less variance.
Hence, we are back at the bias variance tradeoff
Bias variance tradeoff
The bias-variance tradeoff is the property of a model that the variance of the parameter estimated across samples can be reduced by increasing the bias in the estimated parameters.

image source
It seems counterintuitive to induce bias - however, the MSE is composed of bias, variance and irreducible error. Optimizing for the bias and variance makes sense and yields better performance.
Bias variance tradeoff

image source
Regularization methods (i.e. ridge and lasso) introduce bias in the solution that can reduce the variance considerably when compared to e.g. least squares.
Least squares is unbiased: the regression coefficients are without bias.
Yet, the lower variance solution obtained with regularized techniques provides superior performance. At least with respect to the Mean Squared Error.
The curse of dimensionality
## y x ## [1,] 1.0 0.5 ## [2,] 0.8 0.3 ## [3,] 1.1 0.8

The curse of dimensionality
## y x ## [1,] 1.0 0.5 ## [2,] 1.1 0.8

The curse of dimensionality
## y x ## [1,] 1 0.5

So why did ridge work so well?
The ordinary least squares (OLS) solution has low bias and low variance if the response and the predictors are linear in scenarios where there are a large number of observations and everything is well-defined.
If everything is not well-defined, then adding a little more bias will lower the variance and yield a much more efficient MSE.
If the number of cases is much smaller than the number of features (predictors), then the ridge regression will yield far better results:
- the variance of the OLS is then unbiased, but the variance are large. Predictions will then be far away from the actual values.
- ridge regression can reduce this variance without a substantial increase in bias.
An optimal shrinkage parameter needs to be chosen.
What can ridge not do?
- Ridge regression cannot do magic
- Ridge regression cannot think by itself
- Ridge regression cannot determine if some coefficients should be shrunk more than others
- Ridge regression cannot select the most efficient set of features
But Lasso regression can pose an answer to (3) and (4)
Lasso regression
Lasso
Lasso stands for Least Absolute Shrinkage and Selection Operator.
Lasso differs from ridge in two aspects:
1 The lasso uses the \(L^1\)-norm, also known as the Manhattan norm. The \(L_1\)-norm is simply the sum of the absolute values of the coefficients.
- This differs from the ridge regression, which uses the squared \(L_2\), or Euclidian norm. The \(L_2\)-norm defines the distance as the straight line between two points in a space.
2 Because the Lasso poses a restriction on the sum of the absolute coefficients, some coefficients can be set to zero.
- This differs from ridge regression where the shrinkage is applied on all coefficients: the large ones and the small ones.
The goal of Lasso regression is to obtain the subset of predictors that minimizes prediction error.
How does this work
Shrinkage: The Lasso poses a constraint on the model parameters that causes regression coefficients for some variables to shrink toward zero.
- features with coefficients equal to zero after the shrinkage process are excluded from the model.
Selection: The most important features are identified.
- features with non-zero coefficients are most strongly associated with the response variable.
Penalty functions
With ridge regression we had the penalty \[\lambda \cdot \sum_{j=1}^p\beta_j^2 = \lambda \cdot ||\beta||_2^2.\] With the Lasso we have the penalty \[\lambda \cdot \sum_{j=1}^p|\beta_j| = \lambda \cdot ||\beta||_1\]
Lasso vs Ridge: in 2 dimensions

image from ISLR V2
Why use Lasso regression?
Greater prediction accuracy: If there are many more features than cases, the variance of the OLS parameters will be higher.
In such cases, the Lasso can reduce variance without substantially increasing the bias.
Improved model interpretability: When not all features are really associated with the response variable, we end up with an overfitted model that may be difficult to interpret.
With Lasso regression the coefficients for unimportant features are reduced to zero
- this effectively removes the contribution of these features from the model
- the resulting model is more parsimonious
The question is what value of \(\lambda\) would still allow for an efficient and interpretable model.
Create some data
set.seed(123) data <- simulateVCM(n = 200, p = 2000) dim(data$X)
## [1] 200 2000
idx <- createDataPartition(data$Y, p = .7, list = FALSE)
train <- cbind(data$Y, data$X)[idx, ]
test <- cbind(data$Y, data$X)[-idx, ]
colnames(train) <- colnames(test) <- c("Y", paste("X", 1:2000, sep = ""))
Ridge
fit.ridge <- cv.glmnet(x = train[, -1], y = train[, 1], alpha = 0, nfolds = 10) plot(fit.ridge)

Ridge
fit.ridge
## ## Call: cv.glmnet(x = train[, -1], y = train[, 1], nfolds = 10, alpha = 0) ## ## Measure: Mean-Squared Error ## ## Lambda Index Measure SE Nonzero ## min 527.5 25 9.724 0.6649 2000 ## 1se 1611.0 1 9.738 0.6603 2000
Lasso
fit.lasso <- cv.glmnet(x = train[, -1], y = train[, 1], alpha = 1, nfolds = 10) plot(fit.lasso)

Lasso
fit.lasso
## ## Call: cv.glmnet(x = train[, -1], y = train[, 1], nfolds = 10, alpha = 1) ## ## Measure: Mean-Squared Error ## ## Lambda Index Measure SE Nonzero ## min 0.4380 29 5.817 0.5313 17 ## 1se 0.7306 18 6.304 0.6402 3
Visualize
glmnet(x = train[, -1], y = train[, 1], alpha = 1) %>% plot_glmnet(s = fit.lasso$lambda.min)

Coefs
extract.coef(fit.lasso, s = 'lambda.min') %>% datatable()
Coefficients
coefplot(fit.lasso)

Performance
OLS <- lm(train[, 1] ~ train[, -1]) %>% predict(newdata = data.frame(test[, -1])) ridge <- fit.ridge %>% predict(newx = test[, -1], s = "lambda.min") lasso <- fit.lasso %>% predict(newx = test[, -1], s = "lambda.min") caret::postResample(OLS, test[, 1])
## RMSE Rsquared MAE ## NA 0.1312231 NA
caret::postResample(ridge, test[, 1])
## RMSE Rsquared MAE ## 4.130378e+00 5.657441e-07 3.205665e+00
caret::postResample(lasso, test[, 1])
## RMSE Rsquared MAE ## 3.1975103 0.4581614 2.5772173
With Caret
lambda.grid <- seq(0, .5, by = .01)
lasso <- train(train[, -1], train[, 1],
data = train,
method = "glmnet",
metric = "RMSE",
trControl = trainControl("cv", number = 10),
tuneGrid = expand.grid(alpha = 1, lambda = lambda.grid))
Why does caret yield another \(\lambda\)?
plot(lasso)

lasso$bestTune$lambda
## [1] 0.45
So far
The curse of dimensionality poses restrictions on what we can do. There are some fixes:
1 Feature selection
- Filtering: dropping features because of low variance | low correlation with the response | any other reason?
- Wrapper: Fitting different models and compare them. For example, forward/backwards selection, AIC, etc.
- Wrapper techniques are computationally intensive.
2 Penalization / regularization / shrinkage
- Constrain the modeling coefficients
- Aim to set some modeling coefficients to zero
3 Dimension reduction where the aim is to summarize \(p\) features in \(q<p\) features
Interpretability vs Flexibility

image from ISLR V2
Pro’s and Con’s
Ridge and Lasso are aimed at prediction - not inference
Inference is best done by means of maximum likelihood - because its parameter estimates are unbiased.
That said, both Ridge and Lasso regression push coefficients towards zero
- the aim is to make them work better on new data (prediction)
- shrinkage allows for more complex models and avoids overfitting
In scenarios where many features together explain a response variable - ridge regression is the most optimal as its regularization strength does not discriminate over parameters. If the underlying mechanism is sparse, lasso regression is more fitting and can recover the sparse process.
But what if you want both?
Elastic net
Elastic net regularization
The elastic net combines the \(L_2\) regularization of ridge regression with the \(L_1\) regularization properties of the Lasso
- \(L_2\) defines the regularization stength
- \(L_1\) defines the sparseness of the obtained results

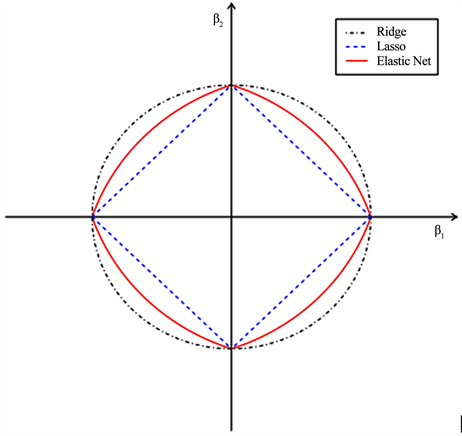{kind=link}
Fiting an elastic net
elastic <- train(train[, -1], train[, 1],
data = train,
method = "glmnet",
metric = "RMSE",
trControl = trainControl("cv", number = 10),
tuneLength = 10)
Visualize
plot(elastic)

Coefs
elastic
## glmnet ## ## 140 samples ## 2000 predictors ## ## No pre-processing ## Resampling: Cross-Validated (10 fold) ## Summary of sample sizes: 125, 128, 126, 125, 126, 126, ... ## Resampling results across tuning parameters: ## ## alpha lambda RMSE Rsquared MAE ## 0.1 0.04897115 2.985127 0.1272443 2.482244 ## 0.1 0.07443179 2.985127 0.1272443 2.482244 ## 0.1 0.11312970 2.985127 0.1272443 2.482244 ## 0.1 0.17194708 2.983985 0.1276212 2.481690 ## 0.1 0.26134428 2.975637 0.1301510 2.477383 ## 0.1 0.39722006 2.963893 0.1336857 2.470419 ## 0.1 0.60373918 2.947317 0.1384887 2.460115 ## 0.1 0.91762987 2.925799 0.1442863 2.446424 ## 0.1 1.39471581 2.893333 0.1566589 2.424410 ## 0.1 2.11984402 2.844691 0.1804431 2.388187 ## 0.2 0.04897115 2.902181 0.1744471 2.407807 ## 0.2 0.07443179 2.902166 0.1744531 2.407763 ## 0.2 0.11312970 2.897430 0.1752430 2.404109 ## 0.2 0.17194708 2.888320 0.1770039 2.397576 ## 0.2 0.26134428 2.877583 0.1795820 2.391653 ## 0.2 0.39722006 2.859515 0.1844729 2.380857 ## 0.2 0.60373918 2.830414 0.1941059 2.356868 ## 0.2 0.91762987 2.783049 0.2119017 2.318436 ## 0.2 1.39471581 2.718404 0.2550304 2.281428 ## 0.2 2.11984402 2.641679 0.3689993 2.238464 ## 0.3 0.04897115 2.845082 0.2094210 2.362533 ## 0.3 0.07443179 2.839228 0.2104677 2.356911 ## 0.3 0.11312970 2.830049 0.2119407 2.348385 ## 0.3 0.17194708 2.821033 0.2134314 2.339748 ## 0.3 0.26134428 2.809780 0.2151369 2.327357 ## 0.3 0.39722006 2.789991 0.2198347 2.312211 ## 0.3 0.60373918 2.735929 0.2413299 2.268975 ## 0.3 0.91762987 2.664814 0.2857171 2.235892 ## 0.3 1.39471581 2.565615 0.3985187 2.176357 ## 0.3 2.11984402 2.579982 0.4937426 2.174572 ## 0.4 0.04897115 2.805039 0.2287639 2.332471 ## 0.4 0.07443179 2.795090 0.2309827 2.323294 ## 0.4 0.11312970 2.784489 0.2332825 2.314200 ## 0.4 0.17194708 2.774755 0.2347076 2.305190 ## 0.4 0.26134428 2.761014 0.2377935 2.288507 ## 0.4 0.39722006 2.721728 0.2535336 2.260720 ## 0.4 0.60373918 2.640870 0.2967034 2.204070 ## 0.4 0.91762987 2.549541 0.3755946 2.153206 ## 0.4 1.39471581 2.499860 0.4872313 2.115986 ## 0.4 2.11984402 2.667122 0.5040885 2.240333 ## 0.5 0.04897115 2.785390 0.2405600 2.310198 ## 0.5 0.07443179 2.770731 0.2435067 2.298610 ## 0.5 0.11312970 2.754307 0.2490350 2.286627 ## 0.5 0.17194708 2.740072 0.2536405 2.272841 ## 0.5 0.26134428 2.714490 0.2614764 2.249050 ## 0.5 0.39722006 2.646049 0.2946194 2.203551 ## 0.5 0.60373918 2.561979 0.3488576 2.152693 ## 0.5 0.91762987 2.453466 0.4663797 2.080812 ## 0.5 1.39471581 2.521367 0.5135172 2.127429 ## 0.5 2.11984402 2.809047 0.4330860 2.344570 ## 0.6 0.04897115 2.780517 0.2428538 2.308913 ## 0.6 0.07443179 2.760556 0.2496727 2.291574 ## 0.6 0.11312970 2.735623 0.2607138 2.266935 ## 0.6 0.17194708 2.713127 0.2678384 2.245973 ## 0.6 0.26134428 2.671341 0.2856049 2.215756 ## 0.6 0.39722006 2.580796 0.3311090 2.158272 ## 0.6 0.60373918 2.489486 0.4023836 2.096026 ## 0.6 0.91762987 2.437138 0.4933705 2.063525 ## 0.6 1.39471581 2.601228 0.5031688 2.191975 ## 0.6 2.11984402 2.929864 0.3653314 2.432959 ## 0.7 0.04897115 2.761160 0.2540732 2.292969 ## 0.7 0.07443179 2.740844 0.2616904 2.270505 ## 0.7 0.11312970 2.713383 0.2730433 2.241319 ## 0.7 0.17194708 2.689418 0.2802803 2.222506 ## 0.7 0.26134428 2.626730 0.3085213 2.183592 ## 0.7 0.39722006 2.537173 0.3568208 2.127327 ## 0.7 0.60373918 2.419605 0.4622714 2.042774 ## 0.7 0.91762987 2.449450 0.5057622 2.067225 ## 0.7 1.39471581 2.706980 0.4596595 2.272943 ## 0.7 2.11984402 3.021196 0.2774863 2.504140 ## 0.8 0.04897115 2.747592 0.2622887 2.276547 ## 0.8 0.07443179 2.722908 0.2714532 2.247162 ## 0.8 0.11312970 2.697903 0.2817167 2.218433 ## 0.8 0.17194708 2.663240 0.2947750 2.203689 ## 0.8 0.26134428 2.580675 0.3317836 2.151326 ## 0.8 0.39722006 2.493004 0.3862164 2.089321 ## 0.8 0.60373918 2.390958 0.4869239 2.022436 ## 0.8 0.91762987 2.484268 0.5155798 2.097283 ## 0.8 1.39471581 2.803749 0.4117404 2.341478 ## 0.8 2.11984402 3.063003 0.1817711 2.538449 ## 0.9 0.04897115 2.744907 0.2657167 2.269939 ## 0.9 0.07443179 2.714433 0.2772163 2.236048 ## 0.9 0.11312970 2.684804 0.2883315 2.206543 ## 0.9 0.17194708 2.638466 0.3064543 2.186828 ## 0.9 0.26134428 2.545225 0.3498147 2.129096 ## 0.9 0.39722006 2.443603 0.4223399 2.047170 ## 0.9 0.60373918 2.391330 0.4960445 2.021023 ## 0.9 0.91762987 2.545377 0.5024709 2.147948 ## 0.9 1.39471581 2.894855 0.3684792 2.406371 ## 0.9 2.11984402 3.063816 NaN 2.539604 ## 1.0 0.04897115 2.739183 0.2692009 2.259623 ## 1.0 0.07443179 2.706123 0.2819749 2.225476 ## 1.0 0.11312970 2.674102 0.2939910 2.201548 ## 1.0 0.17194708 2.610568 0.3198705 2.166905 ## 1.0 0.26134428 2.513618 0.3658359 2.105186 ## 1.0 0.39722006 2.398068 0.4582394 2.013833 ## 1.0 0.60373918 2.400023 0.5015449 2.024413 ## 1.0 0.91762987 2.618381 0.4767960 2.206351 ## 1.0 1.39471581 2.972731 0.3156099 2.467154 ## 1.0 2.11984402 3.063816 NaN 2.539604 ## ## RMSE was used to select the optimal model using the smallest value. ## The final values used for the model were alpha = 0.8 and lambda = 0.6037392.
Performance
The model with the lowest RMSE:
elastic$bestTune
## alpha lambda ## 77 0.8 0.6037392
When looking at performance:
pred <- elastic %>% predict(test[, -1]) postResample(pred, test[, 1])
## RMSE Rsquared MAE ## 3.2260842 0.4711074 2.5787285
With the elastic net we have to optimize over two hyperparamaters.